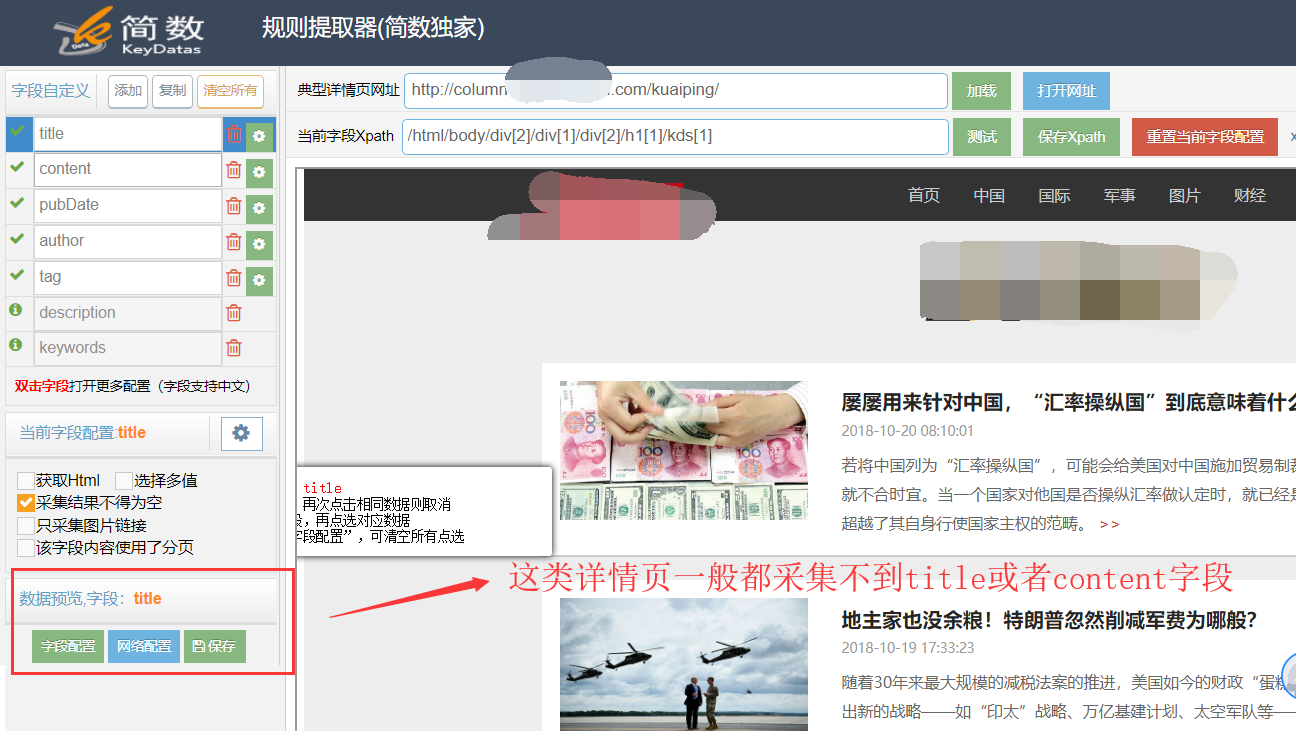
采集技巧:如何不采集非文章頁面的數據
在列表頁提取器選擇要采集的網址鏈接時,中間夾雜著一些多余的頁面鏈接,例如欄目鏈接、廣告鏈接和標簽鏈接等,要怎么解決?
可通過手寫Xpath值來精確選擇鏈接區域來解決。
但有個更簡單的技巧,就是在詳情頁提取器使用 “采集結果不得為空” 功能,因為這些多余的頁面結構排版和常規的文章頁面都不一樣,采集時就會過濾掉這些不符合采集規則的頁面。
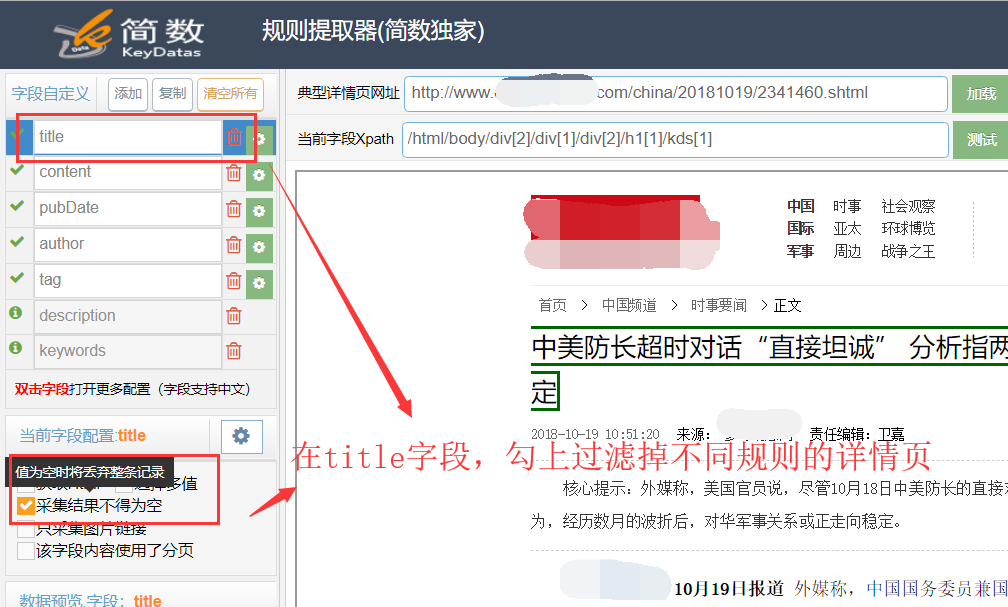
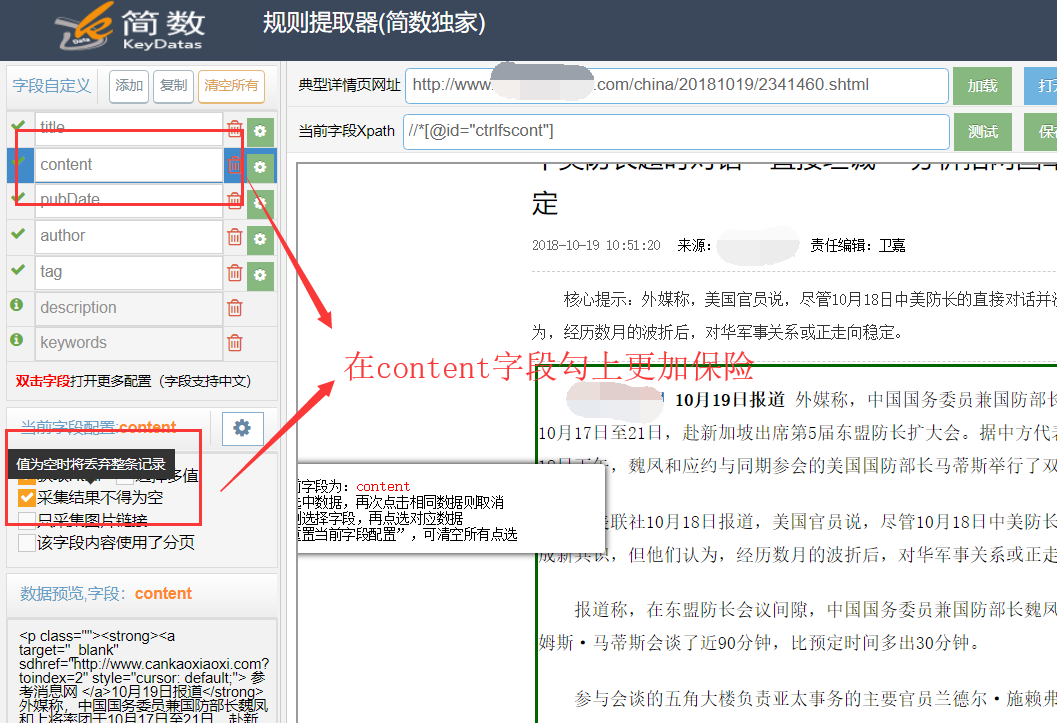
在簡數采集器某個任務的詳情頁提取器,選擇或輸入正確的文章頁面配置采集規則,title 字段和 content 字段處都勾上 “采集結果不得為空”即可。
1)采集文章頁面時
title和content字段采集時都獲取到對應的信息,系統就正常采集入庫這條數據。
2)采集非文章頁面時(例如廣告,列表頁面)
title或者content字段采集時沒有獲取到信息,系統就會過濾不入庫這條數據。